总体思路
结合自身状况,C语言可以令我更流畅地编写操作系统,所以我匆匆准备了C语言的运行环境(C run time),尽可能早地投入C语言的怀抱。loader本应该负责的工作是:进入保护模式,设定分页,设定段描述符,设定中断,加载内核,最后跳转到内核并执行。而我在这里只完成了保护模式的加载,设定了必要的段和栈。反正能用C语言就行,后面可以用C优雅地增加设定或者重新设定。
C语言运行时环境
那什么是C语言运行环境?在我之前的印象中,运行环境只在Java、.Net这样的基于虚拟机的语言中听过。C语言直接编译汇编并链接成机器语言被加载执行,难道也需要一个运行环境?答案是肯定的。不过这里的运行环境不再是什么虚拟机。
C语言编译得到的二进制文件想要运行,需要首先被加载。必然我们需要有一个加载器(loader)。这个加载器将二进制文件按照一定的规则加载进内存,并且需要知道程序的入口地址一遍加载完成后跳转执行。
C程序要运行,我们还需要为它提供内存空间,包括堆栈(因为C使用了堆栈来管理局部变量和函数调用)。为了满足这个条件,一些寄存器需要被初始化。这些寄存器包括段寄存器cs,ds等和栈指针esp。
最后,我们的C语言运行在32位模式下,所以我们需要在进入C语言的代码前先进入保护模式。
投入C语言怀抱
满足上述条件,我们就准备好投入C的怀抱了。具体如何投入呢?思路很简单,用gcc编译一个kernel.c,填充进上一节的紧接着引导去后面的那个扇区。然后跳转到入口并运行。当然上一节的Loader功能只是读取磁盘内容,我们还需要根据上述的内容初始化好C运行环境。
思路归思路,实行起来还是有些麻烦。因为gcc编译出的二进制文件并不是单纯的机器码,还有很多其它信息(元数据)混杂其中。这些信息的目的是提供给操作系统作为加载运行的参考。而我们的内核并没有一个可以使用的应用程序加载器(只有一个简陋的内核加载器)。这些信息对于我们来说是多余的,我们需要提取出纯粹的机器指令,并把它们加载到特定的地址,然后跳转执行————简单又方便。
ELF文件格式不完全笔记
那么如何提取所需机器码?因为编译出来的二进制文件其实是ELF的格式。所以我学习了一下ELF格式。
ELF叫做“可执行/可链接文件格式”。Linux底下可以中GNU的readelf工具读取。该格式图示如下:
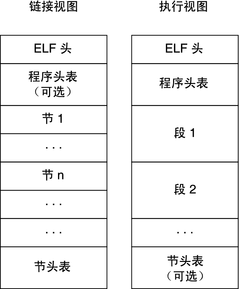
其中的指导程序装载运行或链接的元信息主要是三个头(表)。
/* ELF Header */
typedef struct {
unsigned char e_ident[EI_NIDENT];
Elf32_Half e_type;
Elf32_Half e_machine;
Elf32_Word e_version;
Elf32_Addr e_entry;
Elf32_Off e_phoff;
Elf32_Off e_shoff;
Elf32_Word e_flags;
Elf32_Half e_ehsize;
Elf32_Half e_phentsize;
Elf32_Half e_phnum;
Elf32_Half e_shentsize;
Elf32_Half e_shnum;
Elf32_Half e_shstrndx;
} Elf32_Ehdr;
/* Program Header */
typedef struct elf32_phdr{
Elf32_Word p_type;
Elf32_Off p_offset;
Elf32_Addr p_vaddr; /* virtual address */
Elf32_Addr p_paddr; /* ignore */
Elf32_Word p_filesz; /* segment size in file */
Elf32_Word p_memsz; /* size in memory */
Elf32_Word p_flags;
Elf32_Word p_align;
} Elf32_Phdr;
这里我只展示了两个头,一个是文件头,一个是program头。因为program header中的信息和加载有关,而定位program header需要用到elf header中的信息。没用到的是section header,链接时候才会使用。
在代码段对应的program header的结构中, p_offset指明我们需要的机器码在二进制文件中的偏移。p_vaddr指明代码将要被加载器加载到的地址。我们只需要凭借这两个值,把代码提取出来,并加载到它应该加载到的地址,就可以完成任务。现实情况更简单,因为我们可以在编译是通过设定编译参数指定这个p_vaddr。我们可以让p_vaddr“碰巧”和内核需要被加载的地址一样,这样,我们的loader跳转到内核时,运行的就是这个program header对应段的代码了。
另类的做法
学习了elf格式的有关知识,我们下面讨论如何抽取我们需要的这段代码。正常的做法应该就是写程序去分析各路headers找到代码。注意,这时我们还只能用汇编,因为我们正在构建C运行时的loader部分呀!可是我们不正是想早日用C语言来偷懒嘛?真的不能用C语言吗?
答案是可以的。我说出来大家不要打我。我们可以用C语言编写工具去抽取所需代码。对,是工具,就像编译Linux内核之前,构建系统会提前编译一些工具一样。这些工具不是内核的一部分。它的存在只是为了帮助构建内核。
当然,写这个工具去帮助我们处理elf不仅仅是为了偷懒。我记得引导区512字节的限制,这让我在loader中每增加一行代码时都很惶恐。这样,我们用外部的工具先对elf进行预处理,放得整整齐齐的。这样loader的压力就小了不少。
Makefile
当然,有一些代价,就是构建的指令需要仔细构造。下面是我的Makefile里的部分内容:
gcc elfextract.c -o elfextract #编译elf处理工具
gcc -c -m32 -o kernel.o kernel.c #64位下用-m32编译得到32位代码
nasm -f elf -o lib.o lib.asm #指定elf格式
ld -s -Ttext 0x8000 -o kernel.elf -melf_i386 kernel.o lib.o #-Ttext 0x8000指定程序入口,在我们这里,0x8000 = p_vaddr = kernel_base_phy
./elfextract kernel.elf kernel.bin #提取
nasm -o loader.bin loader.asm
dd if=loader.bin of=a.img conv=notrunc #制作引导区
dd if=kernel.bin of=a.img bs=512 seek=1 conv=notrunc #制作内核
bochs
注意elfextract工具在抽取时只抽取了代码段的内容,C语言编译后的数据段(.bss和.data)都暂时没有引入。所以C语言目前不能使用全局变量 :(
不管怎样,一个汇编文件里的几十行代码,加上精心构造的构建指令和参数,就把我们带入了C语言的机械时代!
关于[BITS 32]
在进入保护模式之后,需要一个跳转来进入32位代码。这里的32位代码需要一个[BITS 32]指令,否则会出错。下面是我搜索得到的一些解释:
BITS指令指定NASM产生的代码是被设计运行在16位模式的处理器上还是运行在32位模式的处理器上。语法是BITS 16或BITS 32。一般在实模式下用16位,保护模式用32位。有些时候一个nasm文件里,同时会处理16或者32位,例如在写实模式跳转到保护模式,在初始化保护模式中最后一句跳转指令所跳到的标号地址一定再[bits 32]下面。不然压栈和指令编码时会出错。
参考
这次笔记其实是在讨论装载器相关话题,列出参考的资料如下:
[1] ORACLE链接程序和库指南: http://docs.oracle.com/cd/E26926_01/html/E25910/chapter6-43405.html
[2] John R. Levine. Linkers & Loaders. Morgan Kaufmann,1999.
[3] 王柏生. 深度探索Linux操作系统:系统构建和原理解析. 机械工业出版社,2013.