xv6是MIT的教学系统,它的源代码是我最喜欢的精致小巧型工程。今天在这里分析xv6的内存管理原理。
内存布局
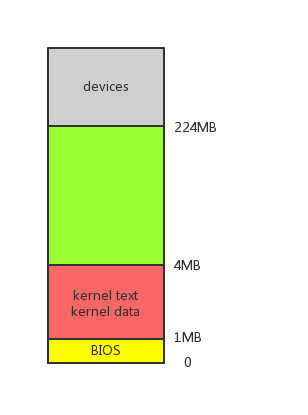
我们首先需要了解的是xv6系统初始化后物理内存的布局情况。如下图所示,xv6内核代码段和数据段被loader加载到主存开始的1MB~4MB的空间内。主存开始0~1MB保留给BIOS存储相关信息。xv6默认主存大小为224MB。4MB~224MB这段内存可以自由分配:可以映射给内核空间或用户空间使用。图中灰色的devices区域是其它设备引入的存储空间,仅供设备自身使用,并不是主存的一部分。
描述完物理内存布局情况后,我们将描述更加复杂的逻辑内存,也即进程地址空间的布局。在这里,内存仅仅只是一个逻辑地址,可能并不对应这物理存储单元。对于逻辑上的“地址空间”,我们更多地使用“映射”描述其用途,而不像上面使用“存放”、“分配”这类词。
进程地址空间布局如下图所示。可以看到2GB内存处是一分水岭。大于2GB的空间属于内核地址空间,小于的属于用户地址空间。
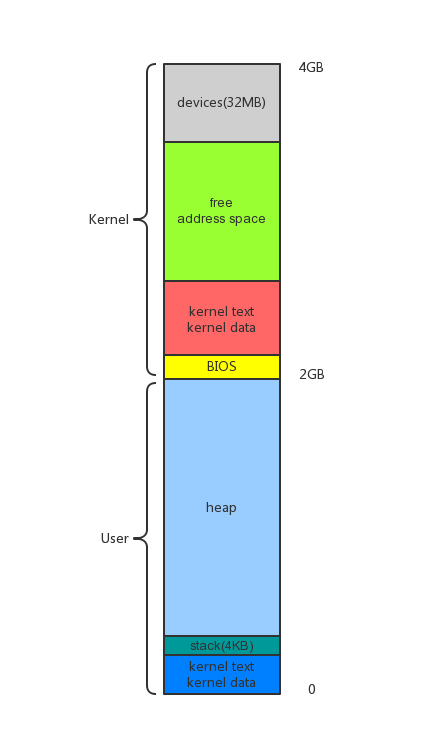
在内核地址空间里,物理内存中开始的内核镜像被映射到2.1GB处。这个地址因此被成为是内核链接(kernel link)地址。x86 32位体系决定了地址空间最大为4GB。末端32MB地址空间映射设备存储。介于设备和内核之间的地址空间为自由地址空间,可用于映射全部物理内存的任意一段。这里之所以强调“全部物理内存”是因为内核地址空间可以寻址整个内存(用户地址空间则不能)。另一个原因和高端内存有关,但高端内存超出了本文讨论范围(似乎xv6本身也没有想考虑高端内存的意愿,毕竟它默认物理内存就224MB)。
在用户地址空间里映射的是用户程序的代码、数据、堆和栈。其中栈的大小只有1个页(4KB)。这是xv6的限制。
那么内存到底是如何被分配的?下面我们主要从分配和映射两个步骤讨论这个问题。
内存分配
内存分配归根结底是指物理内存的分配。其分配单位是物理页框,简称页框。再说一遍,说到“页框”我们就是在说“物理内存”,和地址空间并没有太多关系。
xv6如何去分配一个页框?xv6使用了资源池的概念。它将所有空闲内存(也就是物理内存布局图中的绿色部分)分割成4KB大小的页框,并用链表将它们组织起来。分配一个页框就是从空闲页框链表头摘掉一个返回的过程。作为对应,回收一个页框就是塞回空闲页框链表头的过程。
下面让我们近距离观察上述过程。
初始化资源池
首先,资源池的初始化函数两个如下列代码。系统启动后被main调用。之所以有两个是因为启动时pdt中只存在4MB内存需要使用kinit1初始化。后面建立成熟的页表可以访问所有内存后,再调用kinit2初始化剩余内存。在调用kinit1时并不用锁,也不能锁。因为锁在4MB空间之外。一旦建立好成熟页表后,锁对于保护这个全局链表的安全就相当重要了。
void kinit1(void *vstart, void *vend)
{
initlock(&kmem.lock, "kmem");
kmem.use_lock = 0;
freerange(vstart, vend);
}
void kinit2(void *vstart, void *vend)
{
freerange(vstart, vend);
kmem.use_lock = 1;
}
这两个函数调用freerange()来将一段内存分割成页框:
void freerange(void *vstart, void *vend)
{
char *p;
p = (char*)PGROUNDUP((uint)vstart);
for(; p + PGSIZE <= (char*)vend; p += PGSIZE)
kfree(p);
}
freerange()最终调用kfree()将页框加入空闲页框链表——这是kfree()收拾kalloc()烂摊子外的副业。去掉一些出错判断和锁操作后的kfree()看起来是这样的:
void kfree(char *v)
{
struct run *r;
// Fill with junk to catch dangling refs.
memset(v, 1, PGSIZE);
r = (struct run*)v;
r->next = kmem.freelist;
kmem.freelist = r;
}
其中struct run的定义如下,它被存放在每个页框的开始位置。
struct run {
struct run *next;
};
分配页框
与kfree()对应的函数kalloc()取出锁操作后看起来是这样的:
char* kalloc(void)
{
struct run *r;
r = kmem.freelist;
if(r)
kmem.freelist = r->next;
return (char*)r;
}
小结
内核的链接位置(在逻辑地址空间的位置)固定,物理地址对应的虚拟地址很容易被计算:
virt = phy + KERNBASE
得益于这一点,页框的管理变得非常容易。
页表建立
virt = phy + KERNBASE,为什么能这么简单?因为内核一直映射在每个进程地址空间的相同地址,而且内核的一些组成部分在内存中较为稳定(相对于多种多样还在动态变化的应用程序),内核页表大部分使用直截了当的线性映射就好。然而有些表项,还有进程的页表,有一万个理由变得复杂无比。我们就来看看如何建立这些复杂的内核页表项和进程页表。
内核页表的建立
xv6在main调用kvmalloc()建立新的成熟的内核页表替换原来临时页表。kvmalloc()实际上调用了setkvm()依照kmap表的样子,创建了一个线性映射的页表。
static struct kmap {
void *virt;
uint phys_start;
uint phys_end;
int perm;
} kmap[] = {
{ (void*)KERNBASE, 0, EXTMEM, PTE_W}, // I/O space
{ (void*)KERNLINK, V2P(KERNLINK), V2P(data), 0}, // kern text+rodata
{ (void*)data, V2P(data), PHYSTOP, PTE_W}, // kern data+memory
{ (void*)DEVSPACE, DEVSPACE, 0, PTE_W}, // more devices
};
pde_t* setupkvm(void)
{
pde_t *pgdir;
struct kmap *k;
if((pgdir = (pde_t*)kalloc()) == 0)
return 0;
memset(pgdir, 0, PGSIZE);
for(k = kmap; k < &kmap[NELEM(kmap)]; k++)
if(mappages(pgdir, k->virt, k->phys_end - k->phys_start,
(uint)k->phys_start, k->perm) < 0)
return 0;
return pgdir;
}
setupkvm()首先使用上文描述的kalloc页框分配函数分配了一页内存用来存放Page Directory(PD)。PD每个表项Page Directory Entry(简称PDE)指向一张一页大小的Page Table(PT)。PT的每个表项PTE指向一页大小的内存。PDT、PDE、PT、PTE关系如图:
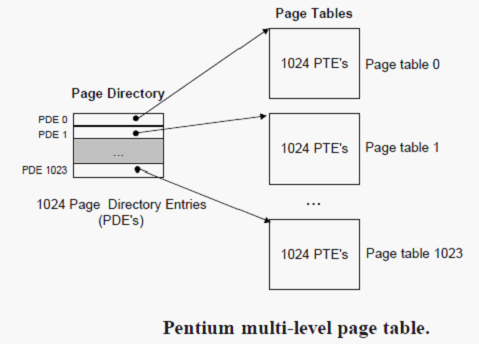
setupkvm()扫描kmap数组的每个元素,调用mappages()构建表项:
static int mappages(pde_t *pgdir, void *va, uint size, uint pa, int perm)
{
char *a, *last;
pte_t *pte;
a = (char*)PGROUNDDOWN((uint)va);
last = (char*)PGROUNDDOWN(((uint)va) + size - 1);
for(;;){
if((pte = walkpgdir(pgdir, a, 1)) == 0)
return -1;
if(*pte & PTE_P)
panic("remap");
*pte = pa | perm | PTE_P;
if(a == last)
break;
a += PGSIZE;
pa += PGSIZE;
}
return 0;
}
注意kmap的每个元素是一段内存区间而非一页,这意味着: 1) kmap的元素对应一个或多个perm相同的页。2) 这些内存区域的起始点和终点并不一定会与页对齐(页是内存对齐的)。mappages()会利用PGROUNDDOW宏进行地址对齐。接着对这个kmap元素指向的内存区间内所有页表进行walkpgdir():
static pte_t * walkpgdir(pde_t *pgdir, const void *va, int alloc)
{
pde_t *pde;
pte_t *pgtab;
pde = &pgdir[PDX(va)];
if(*pde & PTE_P){
pgtab = (pte_t*)p2v(PTE_ADDR(*pde));
} else {
if(!alloc || (pgtab = (pte_t*)kalloc()) == 0)
return 0;
// Make sure all those PTE_P bits are zero.
memset(pgtab, 0, PGSIZE);
// The permissions here are overly generous, but they can
// be further restricted by the permissions in the page table
// entries, if necessary.
*pde = v2p(pgtab) | PTE_P | PTE_W | PTE_U;
}
return &pgtab[PTX(va)];
}
walkpgdir()会去查旬PD中与va相关的PDE索引。如果该PDE存在位被置位,说明对应的PT已存在,否则通过kalloc()分配一个PT。然后查询PT中与va相关的PTE索引,返回该PTE。
再回到上一个mappages()函数。调用完walkpgdir()后检查这个返回值的存在位。如果该位被置位则说明返回的PTE已对应页框——被映射过。这在页表建立时是不应该出现的,会panic。如果没被置位,则登记物理地址和perm位。这样一条页表项便建立完毕。遍历完所有kmap元素的所有页表项,setupkvm()便退出,它的调用者kvmalloc()将会调用switchkvm()重新加载cr3寄存器。
问题:这样,xv6就为kmap描述的静态创建的内核区域构建了页表。思考一下,如何动态申请内存并更新到页表?会不会出现这样的情况?
回答:会。看下一节。
进程页表的建立
进程页表建立时需要先建立内核页表!这就解释了为什么每个进程地址空间都包含了相同的内核空间。
问题:那为什么要在一开始单独建立内核页表?如果内核页表被修改了怎么更新到所有的进程页表?会出现这样的情况吗?
进程页表的构建过程是在exec()函数中完成的。exec()会读取程序ELF信息,找到相应的section,申请内存并将section中数据写入新分配的内存中。
我们并不关心文件读取和ELF格式解析,我们把注意力放在申请内存上。因为这里的申请到的内存和内核页表中映射的内存有些不同——在于它是“申请”来的。上一节提到的内存是静态分配好的,我们是建立了页表项来套它。而这次我们做法不同,我们是先动态申请内存,然后将它登记到页表中去。仔细体会是不是有些差别?
exec()调用allocuvm()来分配物理内存并登记,简化后的allocuvm()会是这个样子:
int allocuvm(pde_t *pgdir, uint oldsz, uint newsz)
{
char *mem;
uint a;
a = PGROUNDUP(oldsz);
for(; a < newsz; a += PGSIZE){
mem = kalloc();
memset(mem, 0, PGSIZE);
mappages(pgdir, (char*)a, PGSIZE, v2p(mem), PTE_W|PTE_U);
}
return newsz;
}
其中有意思的是,新分配的这一页将被映射在进程地址空间的两个地方。换句话说,执行完这段代码后新分配的这一页将会拥有两个页表项。
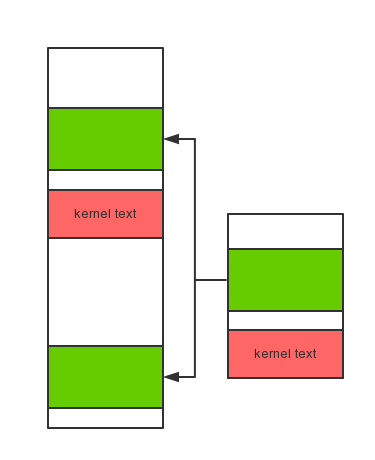
第一次是进程页表的内核部分,这是一开始就在kmap中的:
{ (void*)data, V2P(data), PHYSTOP, PTE_W}, // kern dat
这一段中的一页。也就是这样,我们才可以用
mem = kalloc();
v2p(mem);
这样的方式分配并寻址。
第二次,出现在新登记的页表项中,也就是目前(char*)a被分页机制翻译后所指向的页框。
参考文献
- R. Cox, F. Kaashoek, R. Morris. xv6: a simple, Unix-like teaching operating system.
- xv6 booklet