socket是互联网的基础,我们所熟知的互联网应用大部分是基于socket及其变种,如:浏览器、即时通信软件等。socket这个术语最早出现在TCP规范RFC793中。后来它也作为伯克利编程接口。它的定义为如下二元组:
由此,TCP连接可以定义为:
本文将从socket应用出发,分层深入Linux网络模块内部,去分析内部运行原理。
一个简单的socket应用
1 | //Server |
1 | //Client |
这是一个最简单的可以编译运行的socket应用,简单到省略了出错处理。程序的逻辑为:客户端连接服务器,并发送一个字符串,服务器接收这个字符串并显示。
编程中的要点就是一些库函数的调用。我们把这些函数按顺序排列成下图所示形式。这张图正反映了socket的工作流程。
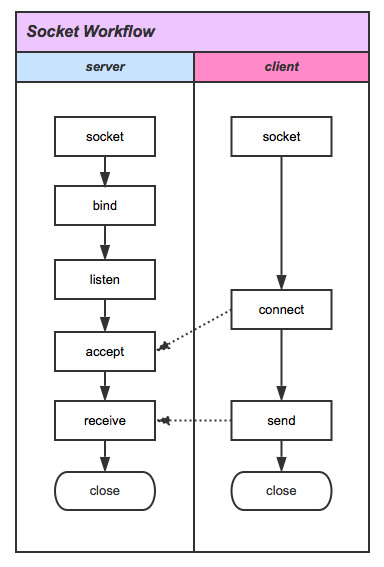
为了完成一次会话,服务器需要预先进入等待连接的状态,即图中的listen调用。为此,服务器首先调用socket创建一个socket文件。至于为什么需要这个文件,是由unix/linux“一切皆是文件”的设计原则决定的。unix/linux中把对网络的操作(配置网络、发送数据包、接收数据包等)都抽象成对socket文件的操作。换句话说,在TCP中,一个socket文件就代表一个socket,一个socket就代表一个网络连接。UDP没有连接的概念,但任然需要一个socket文件作为网络操作的实体。
接着服务器调用bind,为socket绑定本机IP地址和一个没被占用的端口号。计算机网络课程告诉我们,端口号的目的是为了实现复用。通俗一些说,端口号就是为了区分不同进程设置的标识。这些进程都使用网络层收发数据包(复用),端口号就是用来确定正在发送/收到的数据包属于哪个进程。随后,服务器调用listen等待客户端的连接。
下面看图左客户端这边的流程。相比于服务器端,客户端的操作特别简单。依然先调用socket创建一个socket文件作为连接的实体,随后发出connect请求连接。这个请求包含着明确的服务器IP地址和端口号。
服务器收到connect请求后调用accept接受请求。接受请求操作会返回一个新的socket文件。这个文件才是真正与客户端通信的连接所对应的socket文件。accept函数同时会获得客户端的IP地址和端口信息。
至此,双方已经建立连接。此时客户端调用send向服务器发送数据。服务器调用recv接受数据。需要说明的是这个通信是双向的。服务器也可以调用send主动向客户端发送数据。
通信完成后,双方关闭socket文件,释放资源。如果服务器仅仅关闭accept返回的文件,保留最开始的socket文件,那么服务器还有能力接受下一个来自客户端的connect请求(需要一个额外的循环配合listen的调用或者使用多线程)。
内部的故事
如果对于应用程序的编写,上述的知识已经足够了。但是如果想要深入了解Linux内核网络协议栈的实现,我们需要站在较低的层次,仔细观察上述流程发生时内核中的处理和变化。
下图展示了整个网络子系统的层次。为了讨论方便,我们按发送数据包的方向,逐层向下描述各个层次的功能特征。接收数据包的方向是相反的。
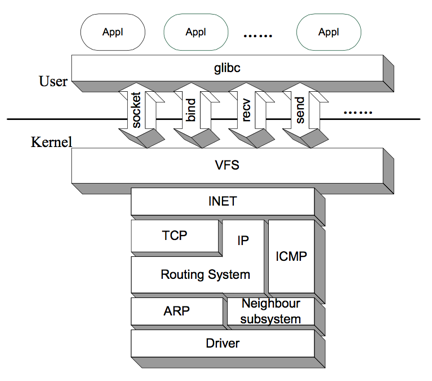
如图所示,系统调用是操作系统内核空间与用户空间的界面。strace工具的结果表明,回溯上述的各个glibc库函数的调用,最终都是系统调用——socket对应sys_socket系统调用,bind对应sys_bind系统调用,send对应sys_sendto系统调用等。
这些系统调用是我们进入内核的入口。进入内核后,VFS(虚拟文件系统)将会进行一些处理。上文说明过,一个socket对应一个socket文件作为操作的实体。本文讨论的这些网络相关的系统调用,都把socket文件作为重要参数,如sys_socket系统就是用来新建并初始化这个socket文件的。sys_bind系统将地址、端口等信息绑定在这个文件上。
离开VFS层,我们下到INET层。这一层的核心数据结构,就是struct socket。每一个socket文件都有一个socket控制实体(数据结构struct socket的实例)与之对应。这个socket控制实体自身以及其成员包含了socket的所有信息,包括状态、标志、操作、数据缓冲区信息等。
有必要说明的是INET这一名称的来历:回顾之前socket应用的例子,可以看到我们调用socket()时曾经传递过一个参数AF_INET。计算机网络课程中我们学习过“细腰结构”——IP over Everything & Everything over IP。但实际上第三层还是有很多不同于IP协议的存在,如IPv6、IPX、DNNET等。Linux称它们为不同的地址簇(Address Families, AF),或叫协议簇(Protocal Families, PF)。INET就是一个地址簇。从另一个角度看,内核代码的net目录下有很多子目录都是一个个独立的地址簇,其中包含一个命名为af_XXX.c的文件用于初始化该地址簇以及提供一些重要的操作。例如在net/ipv4目录中,我们可以看到af_inet.c文件。原来INET就是使用IP(第四版)协议的地址簇!更佳准确的说法是INET封装了TCP/IP。我们在这里只关注TCP/IP协议,只研究INET。
IP和INET有着紧密的联系,但IP层和INET层并不是等价的概念。INET仅仅是使用了IPv4的协议的地址簇,在TCP/IP参考模型中,它不是单独的一层。INET是Linux网络子系统的一个抽象层次,向上提供了操作的接口,但实际还需要调用下层的功能才能完成数据发收、监听等任务。具体调用下层的什么功能,要根据通信类别来选择。TCP/IP协议栈中,通讯有三种类别:TCP、UDP和RAW方式。前两种方式在计算机网络课程中有较多的讨论,大家比较熟悉。最后一种RAW,从某种意义上说,并不是额外的应用层通信方式——它只是告诉应用层不用理会,直接把数据传递到下一层即可,由网络层直接处理。ICMP是基于RAW方式的一个重要协议,只不过它有一些特殊的性质,所以单独列在这里。
如果是发送数据包,数据通过TCP、UDP操作的处理,或是直接通过RAW方式,最终将来到IP层。这一层中出现了重要的数据结构sk_buff(socket buffer的缩写),存储着数据和连接信息,后面操作的中心从之前的socket、sock数据结构转移到sk_buff上来,sock被释放。IP层对数据进行处理后需要对其进行发送。考虑到IP层的一项重要任务是路由,这里的发送不是直接将数据包传递给下面的层次,而是需要在路由系统中进行游历。在Linux中,路由表被称作转发表(Forward Information Base, FIB)。为了提升查找性能,转发表有一个cache叫做rtable(字面意为“路由表”)。为了避免混淆,我们称rtable为转发表的cache。查找路由表的方式同一般的cache机制:首先查找转发表cache,若命中即使用该路由,否则查找转发表,并将路由信息添加进转发表cache。转发表cache是用带桶的hash表实现的,其key是流标识flowi(Flow Identifier),用来唯一确定一条业务流。如果找到合适的路由后,我们就便把发送的数据传递给下层。但也可能发生找不到路由的情况,例如第一次向一台远程主机发送数据。这时,内核将会暂停发送数据的工作,转而完成邻居发现/地址解析(ARP)。
完成这一工作的是图中倒数第二层的ARP和邻居子系统。它们之间类似于包含关系。ARP的功能是将IP地址映射成MAC地址。邻居子系统的功能是将IP地址映射成链路层硬件地址。MAC地址是硬件地址的一种。对于非以太网设备,其硬件地址不一定是MAC地址。所以ARP可以看成是邻居子系统的一个特殊情况。当然地址解析不是每次都能成功的,特别是第一次向某个主机发送数据时。这时邻居系统将会暂停数据发送流程,转而进行邻居发现的流程。这一层次的功能实质是衔接IP层和链路层,开始使用硬件地址,并有了设备的概念。
真正与设备紧密联系的是图中的最后一层:设备驱动层。它位于参考模型中的链路层。正是它控制硬件,将数据包发送出去。虽然内核编程使用的C语言是面相过程的程序设计语言,但Linux的驱动模型具有鲜明的面相对象特征。驱动这一“抽象类”定义了很多虚”方法”,由具体的驱动程序去实现这些”方法“。这些”方法“对应着网卡硬件功能的抽象,由操作系统内核回调,以完成数据收发、网卡配置等任务。
上述讨论部分按照发送数据的流程进行,接收数据与之有很大差别,但任然可以参考反方向进行分析。
附:结合网络模拟器学习计算机网络
本学期刚好选修了一门TCP/IP协议分析与编程的课程,所以想到把篇文章po上博客。文章起草于2016春节,当时的动机是:刚刚修完计算机网络这门课,学到很多很多的概念和协议,但总觉得很虚、不实在。当时认为,学习一个具体系统的网络实现会让这些模糊的概念生动起来,所以选择对开源的Linux内核代码的网络模块进行了调研。
而现在,我找到了更好的一条学习路径。在开学前几天,我回了一趟实验室。就在实验室的这两天,我接触到了一个叫做OMNET++的网络模拟软件。利用OMNET++可以开发自己的网络模拟器,但就学习、验证计算机网络课程学习的知识而言,我们直接运行OMNET++自带的一些实例就可以得到极大的满足。OMNET++编写的模拟器可以用动画的形式展示网络的行为。同时,我们也可以任意停止时间,观察网络中的数据包和各个层次、各个组件的状态。最近我就单步运行了一个DHCP的实例,对照书本中说明的流程,学习了DHCP。只要愿意,我们甚至可以修改代码,改造某一协议,并通过模拟验证修改对整个网络的影响。
从本科学习计算机网络这门课以来到现在,我总结了一个自我认为很爽快的学习路径:
从计算机网络课程学习基本概念 -> 借助模拟器观察实际网络行为 -> 分析开源系统的代码获得具体技术细节实现
之前直接跳过第二环节去分析源代码,现在看来傻乎乎的。缺少一个直觉、系统的认识,那么学习曲线会十分陡峭,常常摸不着头脑。
参考资料
- Linux内核源代码 www.kernel.org
- CSDN专栏Linux内核网络栈源代码分析 http://blog.csdn.net/column/details/linux-kernel-net.html
- PDF Linux-Net 和它的读书笔记 http://www.cnblogs.com/better-zyy/archive/2012/03/16/2400811.html
- PDF Linux TCP/IP协议栈分析(二到五章)
- Linux Manual Page
- http://blog.csdn.net/wearenoth/article/category/1131669
- http://blog.csdn.net/minghe_uestc/article/details/7819925
- http://www.omnetpp.org